


Ever had that moment where you just can’t remember the name of a movie? You can’t remember the names of the actors or the director. All you remember are some clouded instances of the plot, and that’s it!
If you have, then suffer no more! Machine Learning & Natural Language Processing can come to your rescue. 🙌
In this article, we’ll walk through the process of building a solution which can suggest names of the movies you’re talking about based on your vague descriptions.
The story behind it
The inspiration for this solution came while I was developing a solution to enhance the troubleshooting process for frontline workers at Softway. The client had a portal to report all the failures and incidents occurring on-site. Although they had plenty of data, they had no way to perform rich analytics and generate insights from the data they owned. Our team at Softway used data from those historical troubleshooting reports to generate multiple insights which were helpful to them at multiple levels for business. It helped them make better decisions to buy components, help them maintain their machines in a smart & predictive way and help their frontline workforce to troubleshoot issues assisted by data and smart insights. My colleague, Pulkit Shah, has written an interesting article about our escapade.
This article aims to limelight our approach to provide data assisted troubleshooting in a fun & simple manner.
Latent Dirichlet Allocation (aka LDA)
If you’re not already familiar with LDA, it is a generative statistical model widely used for (and originally proposed for) topic modeling. It works on two hypotheses:
- Linguistic items with similar distributions have similar meanings (i.e. comparable topics make use of similar words).
- Each document is a mixture of latent topics (i.e. documents talk about several topics).
The goal of LDA is to score each document against a set of topics which are defined as a set of n-grams associated with them.
In this article, I’ve used LightLDA, a state-of-the-art implementation of LDA which improves sampling throughput and convergence speed via a fast O(1) metropolis-Hastings algorithm, and allows small clusters to tackle very large data and model sizes through model scheduling and data parallelism architecture.
To implement the machine learning pipeline, I’ve used ML.NET, which is an excellent machine learning toolkit built for C# & .NET Core.
Repository & dataset
The complete code of the solution can be found here. The dataset can be found here.
Getting Started
This article only focuses on the Machine Learning & Natural Language Processing part. The complete solution also implements a database (MongoDB) to store and query through the data, which is out of the scope of this article. The code complete solution can be found in the aforementioned GitHub repository.
Create a .NET Core Console Project & add ML.NET to it.
To install or get started with .NET Core click here.
If you have .NET Core already installed, open your command line & create a .NET Core Console project with the following command:
dotnet new console --output MoviesML
Load the created project in the editor of your choice & open Program.cs. Remove the “Hello World!” code.
Add the required NuGet packages
We’ll be installing the ML.NET NuGet package which is a robust Machine Learning framework for C# & the Newtonsoft.Json package for working with JSON using following commands in the CLI.
dotnet add package Microsoft.ML --version 1.4.0
dotnet add package Newtonsoft.Json --version 12.0.3
Make sure the following headers are added to your Program.cs:
using Microsoft.ML;
using MoviesCL.Models;
using Newtonsoft.Json;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
Adding Data Models
Add the following two data model classes to define the training and prediction data.
public class TextData
{
[LoadColumn(0)]
public string Id { get; set; }
[LoadColumn(1)]
public string Title { get; set; }
[LoadColumn(2)]
public string Plot { get; set; }
}
public class PredictionData : TextData
{
public float[] Features { get; set; }
}
Creating the ML pipeline
Add the following code inside the Main() function and replace _dataPath with the path of the .csv file:
var mlContext = new MLContext();
var dataview = mlContext.Data.LoadFromTextFile<TextData>(_dataPath, hasHeader: true, separatorChar: ',');
IEnumerable<TextData> dataEnumerable = mlContext.Data.CreateEnumerable<TextData>(dataview, reuseRowObject: true).Where(item => !string.IsNullOrWhiteSpace(item.Plot));
dataview = mlContext.Data.LoadFromEnumerable(dataEnumerable);
var pipeline = mlContext.Transforms.Text.NormalizeText("NormalizedText","Plot")
.Append(mlContext.Transforms.Text.TokenizeIntoWords("Tokens",
"NormalizedText"))
.Append(mlContext.Transforms.Text.RemoveDefaultStopWords("Tokens"))
.Append(mlContext.Transforms.Conversion.MapValueToKey("Tokens"))
.Append(mlContext.Transforms.Text.ProduceNgrams("Tokens", ngramLength: 3))
.Append(mlContext.Transforms.Text.LatentDirichletAllocation(
"Features", "Tokens", numberOfTopics: 10));
The MLContext is the common context for all ML.NET operations. Once instantiated by the user, it provides a way to create components for data preparation, feature engineering, training, prediction, model evaluation, etc.
The main point of interest here is the pipeline. If you look closely, there are a series of text processing tasks being performed before using the LDA model. These tasks are:
- Normalization: Normalizes the text by applying common casing & removing special characters, etc.
- Tokenization: The process of chopping the given sentence into smaller parts (tokens)
- Stop word removal: Presence of words like articles (a, an, the) and other commonly used words can skew the analysis. So, such words are removed before further processing.
- Producing n-grams: n-grams are bags of words of size ’n’. The size of n-grams must be decided based on the nature of data & required results. In this article, we are using n-grams of size 3.
After producing n-grams, we send the output to the LDA transform to train the model. The number of topics in LDA is set manually. There is no straight-forward way of getting the max number of topics but this can be optimized either by maximizing the log-likeliness or using topic coherence score.
There are two hyperparameters that control document and topic similarity, alphaSum and beta, respectively. A low value of alphaSum will assign fewer topics to each document and vice-versa. A low value of beta will use fewer words to model a topic whereas a high value will use more words, thus making topics more similar between them.
Training and assigning the scores
After creating the pipeline, we will train the model & create a prediction engine to assign scores to each document (movie plot in this case) against each topic.
The complete code in Program.cs looks like:
static async Task Main(string[] args)
{
var mlContext = new MLContext();
var dataview = mlContext.Data.LoadFromTextFile<TextData>(_dataPath, hasHeader: true, separatorChar: ',');
IEnumerable<TextData> dataEnumerable = mlContext.Data.CreateEnumerable<TextData>(dataview, reuseRowObject: true).Where(item => !string.IsNullOrWhiteSpace(item.Plot));
dataview = mlContext.Data.LoadFromEnumerable(dataEnumerable);
var pipeline = mlContext.Transforms.Text.NormalizeText("NormalizedText","Plot")
.Append(mlContext.Transforms.Text.TokenizeIntoWords("Tokens",
"NormalizedText"))
.Append(mlContext.Transforms.Text.RemoveDefaultStopWords("Tokens"))
.Append(mlContext.Transforms.Conversion.MapValueToKey("Tokens"))
.Append(mlContext.Transforms.Text.ProduceNgrams("Tokens", ngramLength: 3))
.Append(mlContext.Transforms.Text.LatentDirichletAllocation(
"Features", "Tokens", numberOfTopics: 10));
// Fit to data.
var transformer = pipeline.Fit(dataview);
mlContext.Model.Save(transformer, dataview.Schema, "model.zip");
// Create a prediction engine.
var predictionEngine = mlContext.Model.CreatePredictionEngine<TextData, PredictionData>(transformer);
List<PredictionData> predictions = new List<PredictionData>();
Console.WriteLine(dataEnumerable.Count());
foreach (var item in dataEnumerable)
{
var pred = predictionEngine.Predict(item);
predictions.Add(pred);
Console.WriteLine(JsonConvert.SerializeObject(pred));
Console.WriteLine();
}
Console.ReadLine();
}
mlContext.Model.Save(transformer, dataview.Schema, "model.zip");
This line saves the trained model as model.zip. You can now import and use this trained model in any project for predicting scores.
Further steps
After having a vector of scores against each row, you can use any database of your choice to store that data. Here’s an example of an MSSQL database containing movie names with topic scores assigned against them.
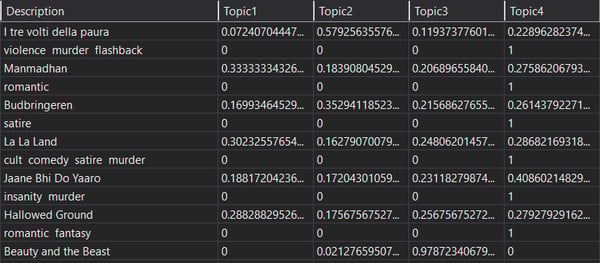
Import the saved model in a new project to consume. You can refer to the code below to consume the model and assign scores.
public static async Task LoadModelAndPredict(string description)
{
var mlContext = new MLContext();
ITransformer trainedModel = mlContext.Model.Load("model.zip", out DataViewSchema modelSchema);
// Creating prediction engine
var predictionEngine = mlContext.Model.CreatePredictionEngine<TextData, TransformedTextData>(trainedModel);
// Create TextData Entity
TextData data = new TextData() { Description = description };
var prediction = predictionEngine.Predict(data);
Console.WriteLine($"{description}");
for (int i = 0; i < prediction.Features.Length; i++)
Console.Write($"{prediction.Features[i]:F4} ");
}
The input text here would be the description of the movie that’s in your mind. After getting the movie's score across each topic, you can query through the data saved in your DB for best matches.
Note: Since each document (movie plot) may talk about multiple topics, the better approach for finding best matches would be to find movies which have a similar score across each topic rather than finding movies belonging to the highest scored topic.
End note
There’s no limit on how far we could go. No boundaries, no lengths! — Eminem
Although the quote was made in a different context, this couldn't hold any truer for the tech landscape today.
LDA and topic modelling can be used to do amazing things like Modelling Musical Influence, Investigating archival data like contexts in which ‘mental health’ has been brought up over time (see Discourse on Mental Health over Time) and helping businesses achieve more by organizing their data and assisting your workforce by making operations more efficient.
Even this article can be beefed up by using Subtitle data from all the movies to make predictions more accurate and even be able to get movies based on dialogs and more!
There’s so much more that can be done using these concepts to make our lives better, from simple applications like this, to helping people be more efficient, to even enhancing tools like elasticsearch or Lucene.
All we must do is keep exploring. Live long & prosper! 🖖

.png?width=352&name=unnamed%20(7).png)
